

.svg)
The Architecture of Edge Computing Hardware: Why Latency, Power and Data Movement Decide Everything
The Architecture of Edge Computing Hardware: Why Latency, Power and Data Movement Decide Everything

Most explanations of edge computing hardware talk about devices instead of architecture. They list sensors, gateways, servers and maybe a chipset or two. That’s useful for beginners, but it does nothing for someone trying to understand how edge systems actually work or why certain designs succeed while others bottleneck instantly.
If you want the real story, you have to treat edge hardware as a layered system shaped by constraints: latency, power, operating environment and data movement. Once you look at it through that lens, the category stops feeling abstract and starts behaving like a real engineering discipline.
Let’s break it down properly.
What edge hardware really is when you strip away the buzzwords
Edge computing hardware is the set of physical computing components that execute workloads near the source of data. This includes sensors, microcontrollers, SoCs, accelerators, memory subsystems, communication interfaces and local storage. It is fundamentally different from cloud hardware because it is built around constraints rather than abundance.
Edge hardware is designed to do three things well:
- Ingest data from sensors with minimal delay
- Process that data locally to make fast decisions
- Operate within tight limits for power, bandwidth, thermal capacity and physical space
If those constraints do not matter, you are not doing edge computing. You are doing distributed cloud.
This is the part most explanations skip. They treat hardware as a list of devices rather than a system shaped by physics and environment.
The layers that actually exist inside edge machines
The edge stack has four practical layers. Ignore any description that does not acknowledge these.
- Sensor layer
Where raw signals are produced. This layer cares about sampling rate, noise, precision, analog front ends and environmental conditions. - Local compute layer
Usually MCUs, DSP blocks, NPUs, embedded SoCs or low power accelerators. This is where signal processing, feature extraction and machine learning inference happen. - Edge aggregation layer
Gateways or industrial nodes that handle larger workloads, integrate multiple endpoints or coordinate local networks. - Backhaul layer
Not cloud. Just whatever communication fabric moves selective data upward when needed.
These layers exist because edge workloads follow a predictable flow: sense, process, decide, transmit. The architecture of the hardware reflects that flow, not the other way around.
Why latency is the first thing that breaks and the hardest thing to fix
Cloud hardware optimizes for throughput. Edge hardware optimizes for reaction time.
Latency in an edge system comes from:
- Sensor sampling delays
- Front end processing
- Memory fetches
- Compute execution
- Writeback steps
- Communication overhead
- Any DRAM round trip
- Any operating system scheduling jitter
If you want low latency, you design hardware that avoids round trips to slow memory, minimizes driver overhead, keeps compute close to the sensor path and treats the model as a streaming operator rather than a batch job.
This is why general purpose CPUs almost always fail at the edge. Their strengths do not map to the constraints that matter.
Power budgets at the edge are not suggestions, they are physics
Cloud hardware runs at hundreds of watts. Edge hardware often gets a few milliwatts, sometimes even microwatts.
Power is consumed by:
- Sensor activation
- Memory access
- Data movement
- Compute operations
- Radio transmissions
Here is a simple table with the numbers that actually matter.
These numbers already explain why hardware design for the edge is more about architecture than brute force performance. If most of your power budget disappears into memory fetches, no accelerator can save you.
Data movement: the quiet bottleneck that ruins most designs
Everyone talks about compute. Almost no one talks about the cost of moving data through a system.
In an edge device, the actual compute is cheap. Moving data to the compute is expensive.
Data movement kills performance in three ways:
- It introduces latency
- It drains power
- It reduces compute utilization
Many AI accelerators underperform at the edge because they rely heavily on DRAM. Every trip to external memory cancels out the efficiency gains of parallel compute units. When edge deployments fail, this is usually the root cause.
This is why edge hardware architecture must prioritize:
- Locality of reference
- Memory hierarchy tuning
- Low latency paths
- SRAM centric design
- Streaming operation
- Compute in memory or near memory
You cannot hide a bad memory architecture under a large TOPS number.
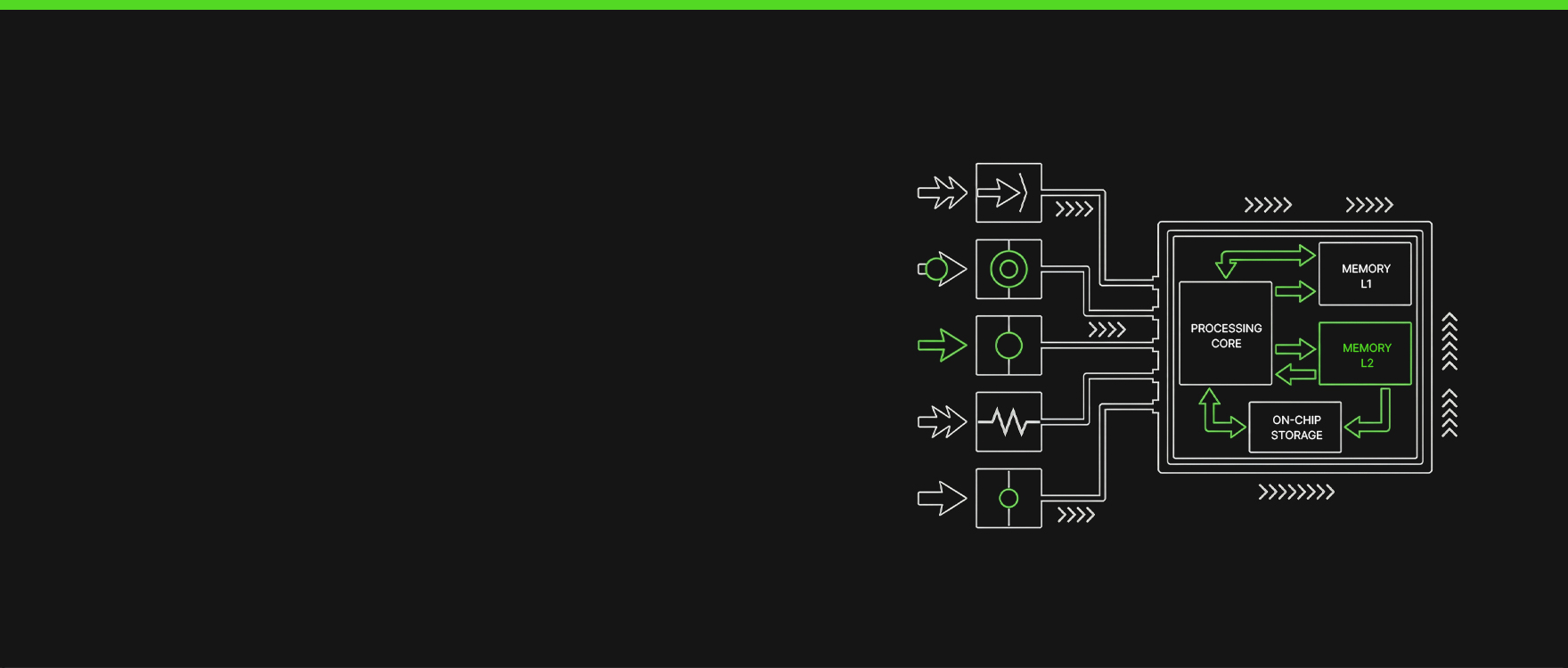
Architectural illustration: why locality changes everything
To make this less abstract, it helps to look at a concrete architectural pattern that is already being applied in real edge-focused silicon. This is not a universal blueprint foredge hardware, and it is not meant to suggest a single “right” way to build edge systems. Rather, it illustrates how some architectures, including those developed by companies like Ambient Scientific, reorganize computation around locality by keeping operands and weights close to where processing happens. The common goal across these designs is to reduce repeated memory transfers, which directly improves latency, power efficiency, and determinism under edge constraints.
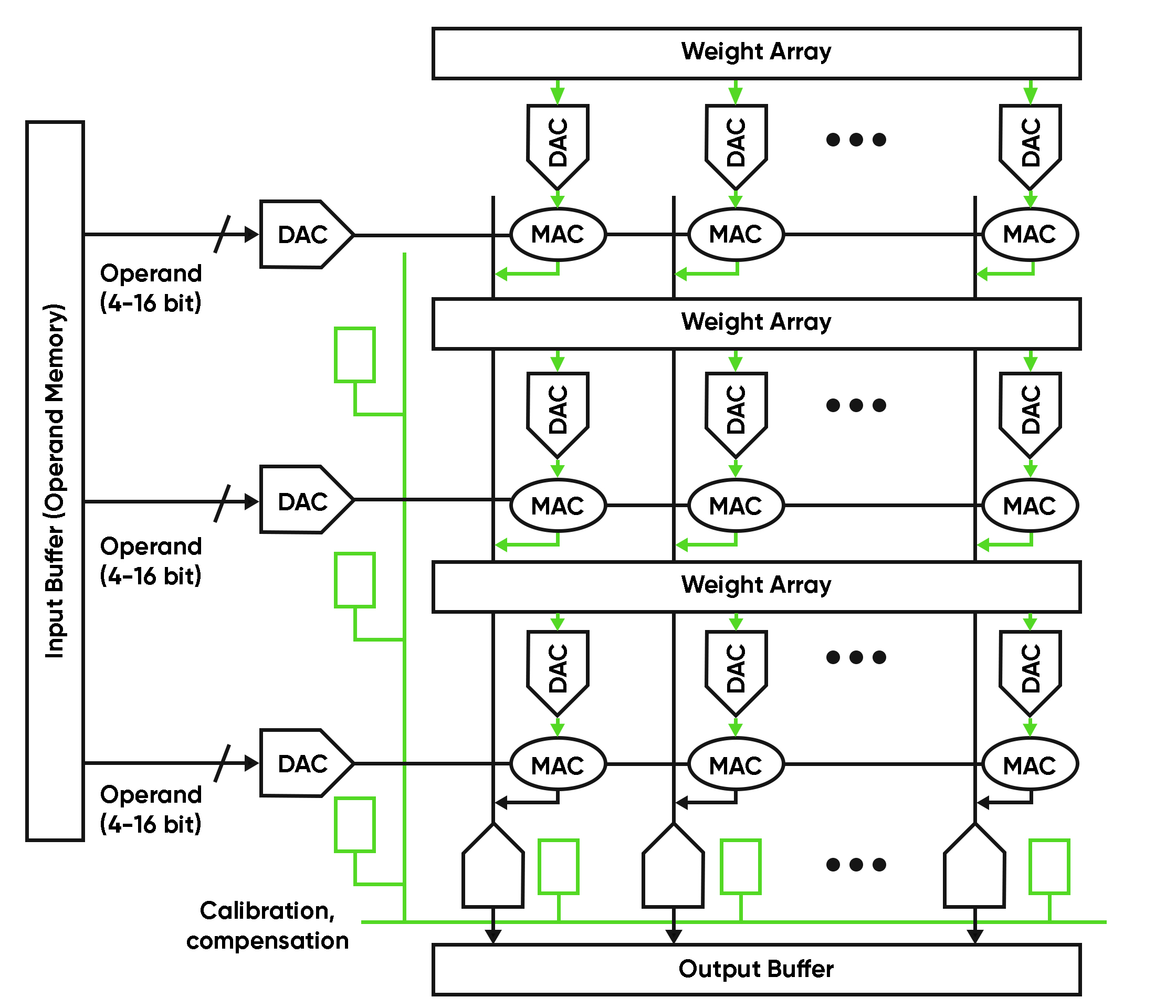
How real edge pipelines behave instead of how diagrams pretend they behave
Edge hardware architecture exists to serve the data pipeline, not the other way around. Most workloads at the edge look like this:
- Sensor produces raw data
- Front end converts signals (ADC, filters,transforms)
- Feature extraction or lightweight DSP
- Neural inference or rule based decision
- Local output or higher level aggregation
If your hardware does not align with this flow, you will fight the system forever. Cloud hardware is optimized for batch inputs. Edge hardware is optimized for streaming signals. Those are different worlds.
This is why classification, detection and anomaly modelsbehave differently on edge systems compared to cloud accelerators.
The trade offs nobody escapes, no matter how good the hardware looks on paper
Every edge system must balance four things:
- Compute throughput
- Memory bandwidth and locality
- I/O latency
- Power envelope
There is no perfect hardware. Only hardware that is tuned to the workload.
Examples:
- A vibration monitoring node needs sustained streaming performance and sub millisecond reaction windows
- A smart camera needs ISP pipelines, dedicated vision blocks and sustained processing under thermal pressure
- A bio signal monitor needs always on operation with strict microamp budgets
- A smart city air node needs moderate compute but high reliability in unpredictable conditions
None of these requirements match the hardware philosophy of cloud chips.
Where modern edge architectures are headed whether vendors like it or not
Modern edge workloads increasingly depend on local intelligence rather than cloud inference. That shifts the architecture of edge hardware toward designs that bring compute closer to the sensor and reduce memory movement.
Compute in memory approaches, mixed signal compute block sand tightly integrated SoCs are emerging because they solve edge constraints more effectively than scaled down cloud accelerators.
You don’t have to name products to make the point. The architecture speaks for itself.
How to evaluate edge hardware like an engineer, not like a brochure reader
Forget the marketing lines. Focus on these questions:
- How many memory copies does a singleinference require
- Does the model fit entirely in local memory
- What is the worst case latency under continuous load
- How deterministic is the timing under real sensor input
- How often does the device need to activate the radio
- How much of the power budget goes to moving data
- Can the hardware operate at environmental extremes
- Does the hardware pipeline align with the sensor topology
These questions filter out 90 percent of devices that call themselves edge capable.
The bottom line: if you don’t understand latency, power and data movement, you don’t understand edge hardware
Edge computing hardware is built under pressure. It does not have the luxury of unlimited power, infinite memory or cool air. It has to deliver real time computation in the physical world where timing, reliability and efficiency matter more than large compute numbers.
If you understand latency, power and data movement, you understand edge hardware. Everything else is implementation detail.


.png)

